
ML-Fundamentals - Bias Variance Tradeoff
Table of Contents
Introduction
If you completed the exercises simple-linear-regression, multivariate-linear-regression and logistic-linear-regression you know how to fit these models according to your training data.
This alone so far has no practical use case. The benefit of learning a model is to predict unseen data. Additionally, only with unseen data your model has not learnt from, it is possible to say if your model generalizes well or not. One way to measure this, is approximating the out of sample error$ E_{out} $, which consists of the measures bias, variance and irreducable error.
In this notebook you will calculate two simple hypothesis for linear regression based on training data and compare them with the use of unseen validation data by calculating$ E_{out} $, which can here decomposed into bias and variance.
Requirements
Knowledge
You should have a basic knowledge of:
- Univariate linear regression
- Out of sample error (bias variance)
Suitable sources for acquiring this knowledge are:
-
Simple Linear Regression Notebook by Christian Herta and his lecture slides (German)
-
Bias Variance Tradeoff by Christian Herta and his lecture slides (German)
Python Modules
By deep.TEACHING convention, all python modules needed to run the notebook are loaded centrally at the beginning.
import numpy as np
import matplotlib.pyplot as plt
import hashlibdef round_and_hash(value, precision=4, dtype=np.float32):
"""
Function to round and hash a scalar or numpy array of scalars.
Used to compare results with true solutions without spoiling the solution.
"""
rounded = np.array([value], dtype=dtype).round(decimals=precision)
hashed = hashlib.md5(rounded).hexdigest()
return hashedExercise
Exercise inspired by lecture 8 from:
- Yaser Abu-Mostafa
- Learning from Data, Caltech Machine Learning [ABU18a]
- or directly at here for the video [ABU18b]
In this exercise, the target function$ t(x) $ is the sin curve. Our task is to approximate the target using a constant function and linear regression, i.e. a straight line. To do so we need training samples from the model. A single training sample is a pair of points on the sin curve, generated as follows: *$ p(x) $ is the uniform distribution in the interval$ [0,2\pi] $
- Two x-values$ x^{(1)} $ and$ x^{(2)} $ are drawn from$ p(x) $
- The y-value is the target of x without any additional noise:$ y^{(i)}= t(x^{(i)}) = sin(x^{(i)}) $

Using these two points, we'll try two different hypotheses to approximate the sin curve: 1. $ \mathcal H_1: h_1(x) = \theta_0 + \theta_1 x $ A straight line through the two points. The parameters$ \theta_0 $ and$ \theta_1 $ correspond to the y-intercept and slope of a linear function. 2. $ \mathcal H_2: h_2(x) = w $ A constant, i.e. a line parallel to the x-axis. To get the constant-curve with minimum squared error just take for$ w $ the mean of the y-values of the two sampled data points.

To judge which of the hypothesis does a better job of modeling the target, we'll generate more training data and learn parameters for the hypotheses. Then we'll evaluate the hypotheses according to the our of sample error, bias and variance.
Task:
-
Do the following 10.000 times:
-
Draw two random examples$ x^{(1)} $ and$ x^{(2)} $ from$ p(x) $ and calculate the corresponding$ y $s to get$ \mathcal D = \{(x^{(1)},x^{(2)}), (y^{(1)},y^{(2)})\} $ (training data)
-
Using your training data calculate the parameters$ \theta_0, \theta_1 $ for$ \mathcal H_1 $ and the parameter$ w $ for$ \mathcal H_2(x) $
-
Numerically calculate the out of sample error$ E_{out} $ for$ \mathcal H_1(x) $ and$ \mathcal H_2(x) $ for 100 data points uniformly distributed in the interval of$ [0, 2\pi] $ (validation data)
-
Now calculate the average$ \theta_0, \theta_1 $ and$ w $ of all 10.000 experiments.
-
Also calculate the average "out of sample error"$ E_{out} $ for both hypothesis sets$ \mathcal H_1 $ and$ \mathcal H_2 $.
-
Use the above to calculate the bia$ ^2 $ and the variance.
-
Plot the target function$ sin(x) $ together with both average hypotheses$ \tilde h_1(x) $ and$ \tilde h_2(x) $ using the average$ \theta_0, \theta_1 $ and$ w $
-
Considering your results, which hypothesis seems to better model the target function?
Practically this explanation is all you need to solve the exercise. You are free to complete it without any further guiding or by proceeding with this notebook.
Data Generation
Task:
Implement the function to draw two random training examples$ (x^{(i)},y^{(i)}) $ with:
-$ x^{(i)} \in Uniform(0,2\pi) $ -$ i \in \{1,2\} $ -$ y^{(i)} = sin(x^{(i)}) $
def train_data():
raise NotImplementedError()x_train, y_train = train_data()
print(x_train, y_train)[1.61668009 0.64093949] [0.99894752 0.59794874]
# If your implementation is correct, these tests should not throw an exception
assert len(x_train) == 2
assert len(y_train) == 2
np.testing.assert_array_equal(np.sin(x_train), y_train)
for i in range(1000):
x_tmp, _ = train_data()
assert x_tmp.min() >= 0.0
assert x_tmp.max() <= 2*np.piHypothesis
For our training data we will now model two different hypothesis sets:
$ \mathcal H_1: h_1(x) = \theta_0 + \theta_1 x $
and
$ \mathcal H_2: h_2(x) = w $
Task:
Implement the functions to calculate the parameters$ \theta_0, \theta_1 $ for$ h_1 $ and$ w $ for$ h_2 $ using the two drawn examples.
For later purpose (passing functions as argument) it is important that both functions accept the same amount of parameters and also return the same amount. Therefore we also pass$ x $ to get_w, although we do not need it. And for the same reason get_thetas should return a list of two values instead of two separate values.
def get_thetas(x, y):
raise NotImplementedError()
def get_w(x, y):
raise NotImplementedError()thetas = get_thetas(x_train, y_train)
w = get_w(x_train, y_train)
print(thetas[0], thetas[1])
print(w)0.3345427085503865 0.41096863886921653
0.798448131419517
# If your implementation is correct, these tests should not throw an exception
x_train_temp = np.array([0, 1])
y_train_temp = np.array([np.sin(x_i) for x_i in x_train_temp])
thetas_test = get_thetas(x_train_temp, y_train_temp)
w_test = get_w(x_train_temp, y_train_temp)
np.testing.assert_almost_equal(thetas_test[0], 0.0)
np.testing.assert_almost_equal(thetas_test[1], 0.8414709848078965)
np.testing.assert_almost_equal(w_test, 0.42073549240394825)Task:
Implement the hypothesis$ h_1(x) $ and$ h_2(x) $. Your function should return a function.
def get_hypothesis_1(thetas):
raise NotImplementedError()
def get_hypothesis_2(w):
raise NotImplementedError()# we want to compute numerically the expectation w.r.t. x
# p(x) is const. in the intervall [0, 2pi]
x_grid = np.linspace(0, 2*np.pi, 100)
y_grid = np.sin(x_grid)# If your implementation is correct, these tests should not throw an exception
h1_test = get_hypothesis_1(thetas_test)
h2_test = get_hypothesis_2(w_test)
np.testing.assert_almost_equal(h1_test(x_grid)[10], 0.5340523361780719)
np.testing.assert_almost_equal(h2_test(x_grid)[10], 0.42073549240394825)Plot
Following the original exercise it is not yet necessary to plot anything. But it also does not hurt to do so, since we need to implement code for the plot anyways.
Task:
Write the function to plot:
- the two examples$ (x^{(1)},y^{(2)}) $ and$ (x^{(2)},y^{(2)}) $
- the true target function$ sin(x) $ in the interval$ [0, 2 \pi] $.
- the hypothesis$ h_1(x) $ in the interval$ [0, 2 \pi] $
- the hypothesis$ h_2(x) $ in the interval$ [0, 2 \pi] $
Your plot should look similar to this one:
def plot_true_target_function_x_y_h1_h2(x, y, hypothesis1, hypothesis2):
raise NotImplementedError()x_train, y_train = train_data()
thetas = get_thetas(x_train, y_train)
w = get_w(x_train, y_train)
plot_true_target_function_x_y_h1_h2(x_train, y_train, get_hypothesis_1(thetas), get_hypothesis_2(w))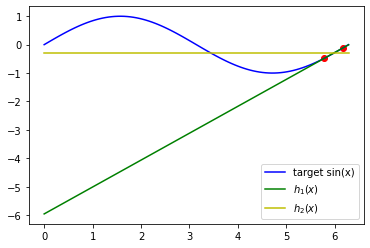
Out of Sample Error
The out of sample error$ E_{out}(h) $ is the expected error on new unseen data.
$ E_{out}(h) = \mathbb E_{x,y}[loss(h(x), y)] = \int_{\mathcal X \times \mathcal Y} loss(h(x), y) p(x,y) dx dy $
In our example we don't need to take the expectation w.r.t.$ y $ because we have have no noise:
$ E_{out}(h) = \mathbb E_{x}[loss(h(x), t(x))] = \int_{\mathcal X } loss(h(x), t(x)) p(x) dx $
Here, we will compute the out of sample error$ E_{out}(h) $ numerically.
We already have discretized the$ x $-axis (x_grid) for$ p(x)\neq 0 $.
So, to compute the expectation we just need to average over x_grid (remember$ p(x) $ is uniform).
$ E_{out}(h) = \mathbb E_{x}[loss(h(x),t(x))] \approx \frac{1}{m} \sum_{j=1}^{m} loss(h(x^{(j)}), y^{(j)}) $
with
-$ m $: number of elements in x_grid
-$ x^{(j)} $ is the$ j $-element of x_grid
Task:
Implement the function to numerically calculate the out of sample error$ E_{out} $ with the mean squared error as loss function.
def out_of_sample_error(y_preds, y):
raise NotImplementedError()# If your implementation is correct, these tests should not throw an exception
e_out_h1_test = out_of_sample_error(h1_test(x_grid), y_grid)
np.testing.assert_almost_equal(e_out_h1_test, 11.52548591)# Note: The data for the test have a high out of sample error 11.525
plt.plot(x_train_temp,y_train_temp, "r*")
plt.plot(x_grid, h1_test(x_grid), "g-")
plt.plot(x_grid, y_grid, "b-")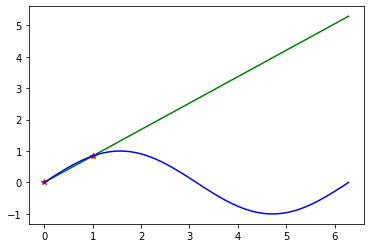
Repeat
Task:
Now instead of drawing two examples (one training data set), draw
now 10.000 times different training sets with two examples.
Calculate$ E_{out} $ for the different$ h_1 $ and$ h_2 $ numerically.
For each run, keep track of the following parameters and return them at the end of the function: -$ \{x^{(1)},x^{(2)}\} $ -$ \{y^{(1)},y^{(2)}\} $ -$ \theta_0 $ -$ \theta_1 $ -$ w $ -$ E_{out} $
def run_experiment(m):
xs = np.ndarray((m,2))
ys = np.ndarray((m,2))
t0s = np.ndarray(m)
t1s = np.ndarray(m)
ws = np.ndarray(m)
e_out_h1s = np.ndarray(m)
e_out_h2s = np.ndarray(m)
raise NotImplementedError()
return xs, ys, t0s, t1s, ws, e_out_h1s, e_out_h2sx_grid.shapenum_training_data = 10000
xs, ys, t0s, t1s, ws, e_out_h1s, e_out_h2s = run_experiment(num_training_data)Average and Plot
Now we can calculate the average of$ \theta_0, \theta_1 $,$ w $ and$ E_{out} $ and already plot the resulting averaged$ \tilde h_1(x) $ and$ \tilde h_2(x) $ together with the target function$ sin(x) $.
Your plot should look similar to the one below:
t0_avg = t0s.mean()
t1_avg = t1s.mean()
thetas_avg = [t0_avg, t1_avg]
w_avg = ws.mean()
h1_avg = get_hypothesis_1(thetas_avg)
h2_avg = get_hypothesis_2(w_avg)
print(thetas_avg)[0.7980074216299939, -0.2541825096801001]
plot_true_target_function_x_y_h1_h2([], [], h1_avg, h2_avg)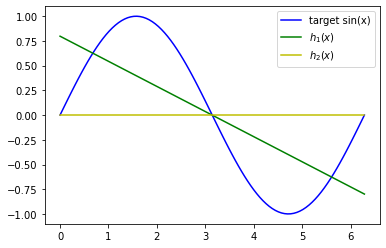
expectation_Eout_1 = e_out_h1s.mean()
print ("expectation of E_out of model 1:", expectation_Eout_1)expectation of E_out of model 1: 1.863109664552461
expectation_Eout_2 = e_out_h2s.mean()
print ("expectation of E_out of model 2:", expectation_Eout_2)expectation of E_out of model 2: 0.7466501937264948
Bias
The bias for the mean-squared error is: $ bias^2 = \mathbb E_{x,y} \left[(\tilde h(x) - y)^2\right] $
The expectation w.r.t.$ y $ vanishes if we have no noise:
$ bias^2 = \mathbb E_x \left[(\tilde h(x) - t(x))^2\right] $
with:
- the average hypothesis$ \tilde h(x) $
Task:
Implement the function to calculate the expecation of the bia$ ^2 $ numerically.
def bias_square(y_true, y_avg):
"""
Returns the bias^2 of a hypothesis set for the sin-example.
Parameters:
y_true(np.array): The y-values of the target function
at each position on the x_grid
y_avg(np.array): The y-values of the avg hypothesis
at each position on the x_grid
Returns:
variance (double): Bias^2 of the hypothesis set
"""
raise NotImplementedError()bias_1 = bias_square(y_grid, h1_avg(x_grid))
print ("Bias of model 1:", bias_1)Bias of model 1: 0.2087361457683148
bias_2 = bias_square(y_grid, h2_avg(x_grid))
print ("Bias of model 2:", bias_2)Bias of model 2: 0.49500121725552587
Variance
Variance for the mean-squared-error:
$ variance = \mathbb E_D \left[ \mathbb E_x \left[\left(h^D(x) - \tilde h(x)\right)^2 \right] \right] $
with:
- the average hypothesis$ \tilde h(x) $
- the learned hypothesis$ h^D(x) $ for training data set$ D $.
Task:
Implement the function to calculate the variances for each of the 10.000 experiments and return them as list or array.
Now we benefit from our implementation of get_w, get_thetas, respectively get_hypothesis1,get_hypothesis2, which accept and return the same amount of parameters, so we can write a generalized function.
def variances(hypothesis_func, param_func, xs, ys, x_grid, y_avg):
'''
Returns the variance of a hypothesis set for the sin-example.
Parameters:
hypothesis_func (function): The hypothesis function 1 or 2
param_func (function): the function to calculate the parameters
from the training data, i.e., get_theta or get_w
xs(np.array): 2D-Array with different training data values for x
first dimension: differerent training data sets
second dimension: data points in a data set
ys(np.array): 2D-Array with different training data values for y
first dimension: differerent training data sets
second dimension: data points in a data set
x_grid(np.array): The x-values for calculating the expectation E_x
y_avg(np.array): The y-values of the average hypothesis at the
positions of x_grid
Returns:
variance (double): Variance of the hypothesis set for
a type for training data
(here two examples per training data set)
'''
return NotImplementedError()var_hypothesis_set_1 = variances(get_hypothesis_1,
get_thetas,
xs, ys,
x_grid,
h1_avg(x_grid))
print(var_hypothesis_set_1)1.6543735187841462
var_hypothesis_set_2 = variances(get_hypothesis_2,
get_w,
xs, ys,
x_grid,
h2_avg(x_grid))
print(var_hypothesis_set_2)0.25164897647096884
print("model 1: E_out ≈ bias^2 + variance: %f ≈ %f + %f" % (expectation_Eout_1, bias_1, var_hypothesis_set_1))
print("model 2: E_out ≈ bias^2 + variance: %f ≈ %f + %f" % (expectation_Eout_2, bias_2, var_hypothesis_set_2))model 1: E_out ≈ bias^2 + variance: 1.863110 ≈ 0.208736 + 1.654374
model 2: E_out ≈ bias^2 + variance: 0.746650 ≈ 0.495001 + 0.251649
Questions
- What do you think is more important for the selection of the appropriate model complexity of the hypothesis set:
- Complexity of the target function or
- the number of training data
-
What do you think happens, if the number of training data increases.
- How change$ E_{out} $ of hypothesis sets 1 and 2?
- How change the bias of hypothesis sets 1 and 2?
- How change the variance of hypothesis sets 1 and 2?
Licenses
Notebook License (CC-BY-SA 4.0)
The following license applies to the complete notebook, including code cells. It does however not apply to any referenced external media (e.g., images).
Exercise: Bias Variance Tradeoff
by Christian Herta, Klaus Strohmenger
is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Based on a work at https://gitlab.com/deep.TEACHING.
Code License (MIT)
The following license only applies to code cells of the notebook.
Copyright 2018 Christian Herta, Klaus Strohmenger
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.