
ML-Fundamentals - Logistic Regression and Regularization
Table of Contents
Introduction
In this exercise you will implement the logistic regression. Opposed to the linear regression, the purpose of this model is not to predict a continuous value (e.g. the temperature tomorrow), but to predict a certain class: For example, whether it will rain tomorrow or not. During this exercise you will:
- Recap (and learn) the fundamentals of logistic regression: Costfunction, Gradient descent for logistic regression
- Implement the logistic function and plot it
- Implement the hypothesis using the logistic function
- Write a function to calculate the cross-entropy cost
- Implement the loss function using the hypothesis and cost
- Implement the gradient descent algorithm to train your model (optimizer)
- Visualize the decision boundary together with the data
- Calculate the accuracy of your model
- Extend your model with regularization
- Calculate the gradient for the loss function with cross-entropy cost (pen&paper)
Requirements
Knowledge
You should have a basic knowledge of:
- Logistic regression
- Cross-entropy loss
- Gradient descent
- numpy
- matplotlib
Suitable sources for acquiring this knowledge are:
- Logistic Regression Notebook by Christian Herta and corresponding lecture slides (German)
- Regularization Notebook by Christian Herta and corresponding lecture slides (German)
- Chapter 5.1 of Deep Learning by Ian Goodfellow
- Some parts of chapter 1 and 3 of Pattern Recognition and Machine Learning by Christopher M. Bishop
- numpy quickstart
- Matplotlib tutorials
Python Modules
By deep.TEACHING convention, all python modules needed to run the notebook are loaded centrally at the beginning.
# External Modules
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inlineExercise - Logistic Regression
Pen & Paper Exercises
Task
Why is
$ \text{arg}\max_x f(x) = \text{arg}\min_x \left[ - \log f(x) \right] $
Logistic model
In logistic regression, the prediction of a learned model$ h_\Theta(\vec x) $ can be interpreted as the prediction that$ \vec x $ belongs to the positive class$ 1 $:
$ p(y=1\mid \vec x; \Theta) = h_\Theta(\vec x) $
Task
What is the probability of the negative class$ p(y=0\mid \vec x; \Theta) $ prediction (expressed with$ h_\Theta(\vec x) $)?
Loss
The loss of an example$ (\vec x^{(i)}, y^{(i)}) $ with target value$ y^{(i)}=1 $ is $ loss_{(\vec x^{(i)}, 1)} (\Theta) = - \log p(y=1\mid \vec x; \Theta) $
The loss of an example$ (\vec x^{(i)}, y^{(i)}) $ with target value$ y^{(i)}=0 $ is $ loss_{(\vec x^{(i)}, 0)} (\Theta) = - \log p(y=0\mid \vec x; \Theta) $
So,$ p(y=k\mid \vec x; \Theta) $ is maximized for the target class$ k $ "by searching
in the$ \Theta $-space".
$ p(y=k\mid \vec x; \Theta) $ is called likelihood of$ \Theta $ (of one example$ (\vec x, y) $)
if it is considered as a function of$ \Theta $.
Note that the likelihood is a function of$ \Theta $.
$ \mathcal L^{(i)}(\Theta) = \log p(y^{(i)}\mid \vec x^{(i)}; \Theta) $ is the log-likelihood
of$ \Theta $ for an example$ i $.
Why is$ p(y=k\mid \vec x; \Theta) $ not a probability with respect to$ \Theta $. Which property of a probability does not hold?
i.i.d. and log-likelihood for all data
Note that the training data in logistic regression should be i.i.d. (independent and identically distributed):
An simple example of an i.i.d. data set is the toin coss of a (marked) coin.
Assume that the probability of head (class$ y=1 $) is$ 0.4 $, i.e.$ p(y=1)=0.4 $.
The probability of getting two heads in two throws is$ 0.4 \cdot 0.4 $:
- Each throw has the same distribution (here:$ p(y=1)=0.4 $. Each throw of the same coin is identically distributed
- The throws are independent. If we get a head on the first throw the probability of getting a head on the second throw does not change.
So, the probability factorizes:$ p(y^{(1)}=1, y^{(2)}=1)=p(y^{(1)}=1)p(y^{(2)}=1) $
For our classification problem: $ p(\mathcal D_y \mid \mathcal D_x; \Theta) = \prod_i p(y=y^{(i)}\mid \vec x^{(i)}; \Theta) $
with -$ \mathcal D_x= \{x^{(1)}, x^{(2)}, \dots , x^{(m)}\} $ -$ \mathcal D_y= \{y^{(1)}, y^{(2)}, \dots , y^{(m)}\} $ -$ \mathcal D $ is the combination of$ \mathcal D_x $ with$ \mathcal D_y $:$ \mathcal D= \{ (\vec x^{(1)},y^{(1)}), (\vec x^{(2)},y^{(2)}), \dots , (\vec x^{(m)},y^{(m)})\} $.
Task
For the whole data set the log-likelihood$ \mathcal L_\mathcal D(\Theta) $ of a parameter set$ \Theta $ is $ \log p(\mathcal D_y \mid \mathcal D_x; \Theta) $).
Note: The (log-)likelihood$ \mathcal L_\mathcal D(\Theta) $ is a function of the parameters$ \Theta $.
Never say the (log-)likelihood of the data.
-
What is$ \mathcal L_\mathcal D(\Theta) = \log p(\mathcal D_y \mid \mathcal D_x; \Theta) $ expressed by the$ p(y^{(i)}\mid \vec x^{(i)}; \Theta) $?
-
What is the relation of the log-likelihood$ \mathcal L^{(i)}(\Theta) $ (for the individual examples$ (\vec x^{(i)}, y^{(i)}) $) to the log-likelihood$ \mathcal L_\mathcal D(\Theta) $ for the whole data set.
In logistic regression the cost function is the negative log-likelihood divided by the number of data examples$ m $:
$ J (\Theta) = - \frac{\mathcal L_\mathcal D(\Theta)}{m} $
The average log-likelihood per data point.
- What is the relation of the (log-)likelihood with the cost function for logistic-regression?
- Derive the cost function of logistic-regression by using your result of 2.
$ h_\Theta(\vec x^{(i)}) = p(1\mid \vec x^{(i)}; \Theta) $
$ 1 - h_\Theta(\vec x^{(i)}) = p(0\mid \vec x^{(i)}; \Theta) $
Derivative of the logistic function
The sigmoid activation function is defined as$ \sigma (z) = \frac{1}{1+\exp(-z)} $
Task:
Show that: $ \frac{d \sigma(z)}{d z} = \sigma(z)(1-\sigma(z)) $
Task:
Now show that: $ \frac{\partial \sigma(z)}{\partial \theta_j} = \sigma(z)(1-\sigma(z)) \cdot x_j $
with -$ z=\vec x'^T \vec \theta $
and -$ \vec \theta = (\theta_0, \theta_1, \dots, \theta_n)^T $ -$ \vec x' = (x_0, x_1, \dots, x_n)^T $
Hint: Use the chain rule of calculus.
Task:
Show from
$ \frac{\partial}{\partial \theta_j} J(\theta) = \frac{\partial}{\partial \theta_j} \left( - \frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \log h_\theta({\vec x}^{(i)})+ (1 - y^{(i)}) \log \left( 1- h_\theta({\vec x}^{(i)})\right) \right] \right) $
that
$ \frac{\partial}{\partial \theta_j} J(\theta) = \frac{1}{m} \sum_{i=1}^{m} \left( h_\theta({\vec x}^{(i)})- y^{(i)}\right) x_j^{(i)} $
with the hypothesis$ h_\theta(\vec x^{(i)}) = \sigma(\vec x'^T \vec \theta) $ So, with our classification cost function (from the max-likelihood principle) the partial derivatives (components the gradient) has a simple form.
Hint:
- Make use of your knowledge, that:
$ \frac{\partial h_\theta(\vec x^{(i)})}{\partial \theta_j} = h_\theta(\vec x^{(i)})(1-h_\theta(\vec x^{(i)})) \cdot x_j $ 2. and note that the chain rule for the derivative of the log is:
$ \frac{\partial \log(f(a))}{\partial a} = \frac{\partial \log(f(a))}{\partial f} \frac{\partial f(a)}{\partial a} = \frac{1}{f(a)} \frac{\partial f(a)}{\partial a} $
Programming Exercises
For convenience and visualization, we will only use two features in this notebook, so we are still able to plot them together with the target class. But your implementation should also be capable of handling more (except the plots).
Data Generation
First we will create some artificial data. For each class, we will generate the features with bivariate (2D) normal distribution;
# class 0:
# covariance matrix and mean
cov0 = np.array([[5,-4],[-4,4]])
mean0 = np.array([2.,3])
# number of data points
m0 = 1000
# class 1
# covariance matrix
cov1 = np.array([[5,-3],[-3,3]])
mean1 = np.array([1.,1])
# number of data points
m1 = 1000
# generate m gaussian distributed data points with
# mean and cov.
r0 = np.random.multivariate_normal(mean0, cov0, m0)
r1 = np.random.multivariate_normal(mean1, cov1, m1)plt.scatter(r0[...,0], r0[...,1], c='b', marker='*', label="class 0")
plt.scatter(r1[...,0], r1[...,1], c='r', marker='.', label="class 1")
plt.xlabel("x0")
plt.ylabel("x1")
plt.legend()
plt.show()
X = np.concatenate((r0,r1))
y = np.ones(len(r0)+len(r1))
y[:len(r0),] = 0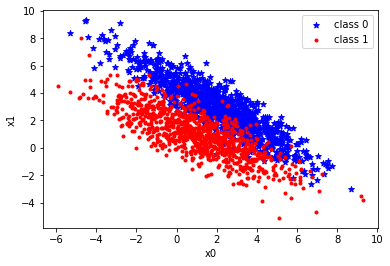
Logistic Function
For the logistic regression, we want the output of the hypothesis to be in the interval$ ]0, 1[ $. This is done using the logistic function$ \sigma(.) $. The logistic function is also called sigmoid function in machine learning:
Task:
Implement the logistic function and plot it in the interval of$ [-10,10] $.
def logistic_function(x):
""" Applies the logistic function to x, element-wise. """
raise NotImplementedError("You should implement this function")
### Insert code to plot the logistic function below
Logistic Hypothesis
The hypothesis in logistic regression is defined by:
$ h_\Theta(\vec x) = \sigma(\vec x'^T \cdot \vec \theta) $
with:
$ \vec x^T = \begin{pmatrix} x_1 & x_2 & \ldots & x_n \\ \end{pmatrix} \text{ and } \vec x'^T = \begin{pmatrix} x_0=1 & x_1 & x_2 & \ldots & x_n \\ \end{pmatrix} $
or for the whole data set$ X $ and$ X' $
$ X = \begin{pmatrix} x_1^{(1)} & \ldots & x_n^{(1)} \\ x_1^{(2)} & \ldots & x_n^{(2)} \\ \vdots &\vdots &\vdots \\ x_1^{(m)} & \ldots & x_n^{(m)} \\ \end{pmatrix} \text{ and } X' = \begin{pmatrix} 1 & x_1^{(1)} & \ldots & x_n^{(1)} \\ 1 & x_1^{(2)} & \ldots & x_n^{(2)} \\ \vdots &\vdots &\vdots &\vdots \\ 1 & x_1^{(m)} & \ldots & x_n^{(m)} \\ \end{pmatrix} $
-$ n $ is the number of features -$ m $ is the number of training data (examples)
Task:
Implement the logistic hypothesis using your implementation of the logistic function. logistic_hypothesis should return a function which accepts the training data$ X $. Example usage:
>> theta = np.array([1.1, 2.0, -.9])
>> h = logistic_hypothesis(theta)
>> print(h(X))
Note: The training data was sampled with random noise, so the actual values of your h(X) may differ.
array([0.03587382, 0.0299963 , 0.97389774, ...,
Hint:
You may of course also implement a helper function for transforming$ X $ into$ X' $ and use it inside the lamda function of logistic_hypothesis.
def logistic_hypothesis(theta):
''' Combines given list argument in a logistic equation and returns it as a function
Args:
thetas: list of coefficients
Returns:
lambda that models a logistc function based on thetas and x
'''
raise NotImplementedError("You should implement this function")
### Uncomment to test your implementation
#theta = np.array([1.,2.,3.])
#h = logistic_hypothesis(theta)
#print(h(X))Cross-entropy loss
The cross-entropy loss for a data point$ ({\vec x}^{(i)}, y^{(i)}) $ is defined by:
\begin{equation} \text{loss}_{({\vec x}^{(i)}, y^{(i)})}(\vec \theta) = -y^{(i)} \cdot log(h_{\Theta} ({\vec x}^{(i)})) - (1-y^{(i)}) \cdot log(1-h_\Theta({\vec x}^{(i)})) \end{equation}
with
- the target class$ y^{(i)} \in \{ 0, 1\} $ of the$ i $-th data point
- the parameters$ \Theta $ packed in the vector$ \vec \theta $. -$ h_{\Theta}({\vec x}^{(i)}) $ the predition for the feature vector of the$ i $-th data point$ \vec x^{(i)} $ with the parameters$ \Theta $ (resp.$ \vec \theta $)
Task:
Implement the cross-entropy loss.
Your python function should return a function, which accepts the vector$ \vec \theta $. This reflects the fact that$ \text{loss}(\vec \theta) $ is a function of the parameter (vector).
The returned function should return the cost for each feature vector$ \vec x^{(i)} $ and target$ y^{(i)} $. The length of the returned array of costs therefore has to be the same length as$ m $ (number of data examples).
Example usage:
>> J = cross_entropy_loss(logistic_hypothesis, X, y)
>> print(J(theta))
Note: The training data was sampled with random noise, so the actual values of your h(X) may differ.
array([ 7.3, 9.5, ....
def cross_entropy_costs(h, X, y):
''' Implements cross-entropy as a function costs(theta) on given traning data
Args:
h: the hypothesis as function
x: features as 2D array with shape (m_examples, n_features)
y: ground truth labels for given features with shape (m_examples)
Returns:
lambda costs(theta) that models the cross-entropy for each x^i
'''
raise NotImplementedError("You should implement this function")
### Uncomment to test your implementation
#theta = np.array([1.,2.,3.])
#costs = cross_entropy_costs(logistic_hypothesis, X, y)
#print(costs(theta))Loss Function
\begin{equation} J_{\mathcal D}(\vec \theta)=\frac{1}{m}\sum_{i=1}^{m}\left(\text{loss}_{({\vec x}^{(i)}, y^{(i)})}(\Theta)\right) \end{equation}
- with the training data$ \mathcal D = \{ (\vec x^{(1)}, y^{(1)}), \dots, (\vec x^{(m)}, y^{(m)}) \} $
Task:
Now implement the loss function$ J $, which calculates the mean costs for the whole training data$ X $. Your python function should return a function, which accepts the vector$ \vec \theta $.
Note: You can ignore the parameter lambda_reg for now, it is a hyperparameter for regularization. In a later exercise, you may revisit your implementation and implement regularization if you wish.
def mean_cross_entropy_costs(X, y, hypothesis, cost_func, lambda_reg=0.1):
''' Implements mean cross-entropy as a function J(theta) on given traning data
Args:
X: features as 2D array with shape (m_examples, n_features)
y: ground truth labels for given features with shape (m_examples)
hypothesis: the hypothesis as function
cost_func: cost function
Returns:
lambda J(theta) that models the mean cross-entropy
'''
raise NotImplementedError("You should implement this")
### Uncomment to test your implementation
#theta = np.array([1.,2.,3.])
#J = mean_cross_entropy_costs(X,y, logistic_hypothesis, cross_entropy_costs, 0.1)
#print(J(theta))Gradient Descent
A short recap, the gradient descent algorithm is a first-order iterative optimization for finding a minimum of a function. From the current position in a (cost) function, the algorithm steps proportional to the negative of the gradient and repeats this until it reaches a local or global minimum and determines. Stepping proportional means that it does not go entirely in the direction of the negative gradient, but scaled by a fixed value$ \alpha $ also called the learning rate. Implementing the following formalized update rule is the core of the optimization process:
\begin{equation} \vec \theta_{new} \leftarrow \vec \theta_{{old}} - \alpha \vec \nabla_\Theta J(\vec \theta_{old}) \end{equation}
Task:
Implement the function to update all$ \theta $ values (in a vectorized way).
Note: You can ignore the parameter lambda_reg for now, it is a hyperparameter for regularization. In a later exercise, you may revisit your implementation and implement regularization.
def compute_new_theta(X, y, theta, learning_rate, hypothesis, lambda_reg=0.1):
''' Updates learnable parameters theta
The update is done by calculating the partial derivities of
the cost function including the linear hypothesis. The
gradients scaled by a scalar are subtracted from the given
theta values.
Args:
X: 2D numpy array of x values
y: array of y values corresponding to x
theta: current theta values
learning_rate: value to scale the negative gradient
hypothesis: the hypothesis as function
Returns:
theta: Updated theta_0
'''
raise NotImplementedError("You should implement this")
### Uncomment to test your implementation
#theta = np.array([1.,2.,3.])
#theta = compute_new_theta(X, y, theta, .1, logistic_hypothesis, .1)
#print(theta)Using the compute_new_theta method, you can now implement the gradient descent algorithm. Iterate over the update rule to find the values for$ \theta $ that minimize our cost function$ J_D(\theta) $. This process is often called training of a machine learning model.
Task:
- Implement the function for the gradient descent.
- Create a history of all theta and cost values and return them.
def gradient_descent(X, y, theta, learning_rate, num_iters, lambda_reg=0.1):
''' Minimize theta values of a logistic model based on cross-entropy cost function
Args:
X: 2D numpy array of x values
y: array of y values corresponding to x
theta: current theta values
learning_rate: value to scale the negative gradient
num_iters: number of iterations updating thetas
lambda_reg: regularization strength
cost_function: python function for computing the cost
Returns:
history_cost: cost after each iteration
history_theta: Updated theta values after each iteration
'''
raise NotImplementedError("You should implement this")
Training and Evaluation
Task:
Choose an appropriate learning rate, number of iterations and initial theta values and start the training
# TODO: Assign sensible values
alpha = 42
theta = np.array([42, -100, 10e5])
num_iters = 1234
history_cost, history_theta = gradient_descent(X, y, theta, alpha, num_iters)<ipython-input-5-1a8b0be84971>:6: RuntimeWarning: overflow encountered in exp
return 1. / (1. + np.exp(-x))
<ipython-input-9-1a7b7be352f6>:14: RuntimeWarning: divide by zero encountered in log
return lambda theta: -y * np.log(h(theta)(X)) - (1-y) * np.log(1. - h(theta)(X))
<ipython-input-9-1a7b7be352f6>:14: RuntimeWarning: invalid value encountered in multiply
return lambda theta: -y * np.log(h(theta)(X)) - (1-y) * np.log(1. - h(theta)(X))
Now that the training has finished we can visualize our results.
Task:
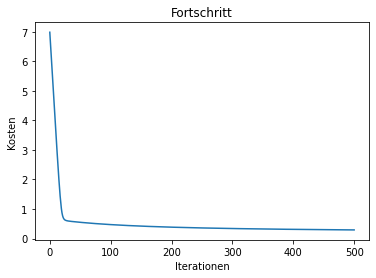
Plot the costs over the iterations. Your plot should look similar to this one:
def plot_progress(costs):
""" Plots the costs over the iterations
Args:
costs: history of costs
"""
raise NotImplementedError("You should implement this!")plot_progress(history_cost)
print("costs before the training:\t ", history_cost[0])
print("costs after the training:\t ", history_cost[-1])costs before the training: 6.981794400056323
costs after the training: 0.2934955386786654
Plot Data and Decision Boundary
Task:
Now plot the decision boundary (a straight line in this case) together with the data.
# Insert your code to plot below
theta_hist[-1]Accuracy
The logistic hypothesis outputs a value in the interval$ ]0,1[ $. We want to map this value to one specific class i.e.$ 0 $ or$ 1 $, so we apply a threshold known as the decision boundary: If the predicted value is < 0.5, the class is 0, otherwise it is 1.
Task:
- Calculate the accuracy of your final classifier. The accuracy is the proportion of the correctly classified data.
- Why will the accuracy never reach 100% using this model and this data set?
# Insert you code belowRegularization
Task:
Extend your implementation with a regularization term$ \lambda $ by adding it as argument to the functions mean_cross_entropy_costs, compute_new_theta and gradient_descent.
Summary and Outlook
During this exercise you learned about logistic regression and used it to perform binary classification on multidimensional data. You should be able to answer the following questions:
- How can you interpret the output of the logistic function?
- For which type of problem do you use linear regression and for which type of problem do you use logistic regression?
Licenses
Notebook License (CC-BY-SA 4.0)
The following license applies to the complete notebook, including code cells. It does however not apply to any referenced external media (e.g., images).
Exercise: Logistic Regression and Regularization
by Christian Herta, Klaus Strohmenger
is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
Based on a work at https://gitlab.com/deep.TEACHING.
Code License (MIT)
The following license only applies to code cells of the notebook.
Copyright 2018 Christian Herta, Klaus Strohmenger
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.